
Transforming the data platform
The need for a revised reference architecture
It is difficult for senior management to build customer relationships with clients if they are unable to access their clients’ data. Executives cannot do quantitative evaluations of data given by large numbers of customers or sources as a consequence. Most businesses depend largely on subjective judgment and external analysis when it comes to client management and growth.
Due to an increasingly strong market rivalry and a lack of knowledge pertaining to customers’ needs, organizations Organizations are seeing a drop in customer loyalty as a result of increased competition and a lack of understanding of consumers’ demands. Every 5% loss in customer loyalty may result in an organization’s profitability decreasing by 2%, according to the data analyzed by Cui and Ding (2018). One-fifth of the expense of getting a new customer is spent on keeping an existing one. Organizations may benefit from the use of data mining in customer relationship management. As a result, applying data mining to customers’ information has risen to the top of the priority list. Data mining may be used to handle a variety of challenges, including:
- determining the trends in a client’s business demands
- identifying the characteristics of high-end consumers
- giving early warning of a customer churn situation
Growing information requirements of rapidly changing business models require a robust yet scalable and adaptable data warehouse (DWH) architecture. Many businesses began their DWH architecture development with a centralized data repository and data marts developed in the manner outlined by Bill Inmon (Inmon, 2011) or with a dimensional data model proposed by Ralph Kimball (Kimball, 2008). Since then, infrastructures have changed throughout time, becoming complex and hybrid based on many architectural principles. In such cases, reference models may assist in framing the DWH approach (Mene et al., 2018).
In addition to IT cost reductions and increased productivity, modernization of data architecture offers to decrease regulatory and operational risk while also enabling the introduction of whole new capabilities, services, and even entire companies (Castro et al., 2020). McKinsey identifies 6 foundational steps towards the adoption of an innovative future-proof data architecture, as presented in figure 1.
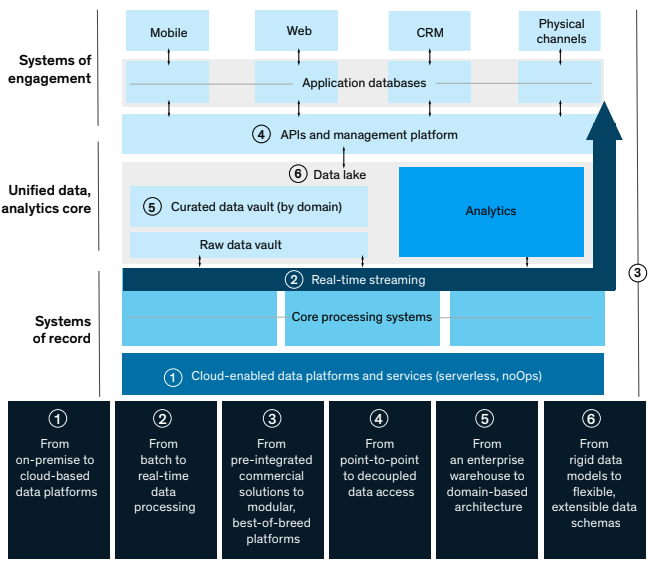
Image Credit: McKinsey
The adoption of cloud computing signalled a shift away from the supply of software and its execution on local servers towards the use of shared data centres and software-as-a-service solutions hosted by platform providers such as Amazon, Google, and Microsoft. A pay-as-you-go cost model that adjusts to unanticipated user needs is promised by the cloud’s shared infrastructure, which offers greater economies of scale, high scalability and availability. As a result, there has been a shift in the demand for the underlying data. Data warehousing professionals are increasingly relying on Big Data technologies such as Hadoop and Spark. Even though they are vital tools for data centre-scale processing jobs, they nevertheless fall short of the efficiency and feature set of established data warehousing systems in many ways. But, perhaps most crucially, they need a significant amount of technical work to implement and maintain (Dageville et al., 2016).
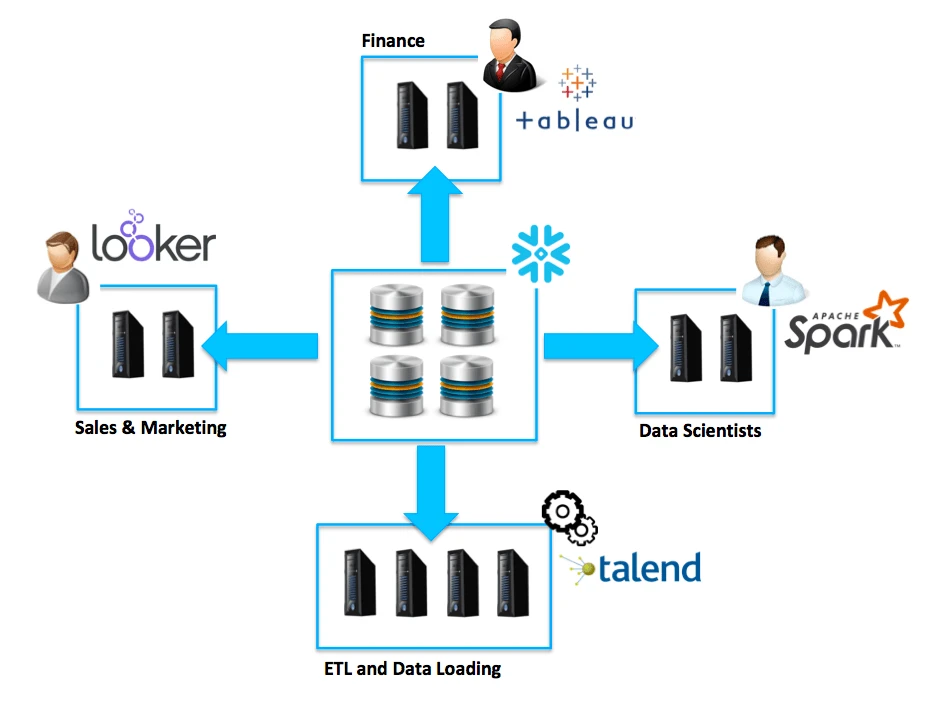
Image Credit: Snowflake
Data Warehouse as a Service
Recent years have seen an increase in the popularity of database as a service, which is supplied via cloud computing platforms. Snowflake Elastic Data Warehouse (Snowflake) is a cloud database service provided by Snowflake Computing. When it comes to database warehousing, the cloud native capabilities of current database systems such as Snowflake open a world of interesting new possibilities. First and foremost, Snowflake has extensive knowledge of prior customer requests, including both the query language and the system parameters that were used in response. Secondly, since Snowflake is multi-tenanted, it enables for easy access to metadata and data that can be used to repeat customer queries from a privileged role, which is advantageous. Snowflake’s data warehouse service is also elastic, which allows testing with these queries to be run on a separate set of resources without interfering with the customer’s production workload (Yan et al., 2018). Additionally, Snowflake utilizes JavaScript Object Notation (JSON) to store information. This underlying data architecture allows businesses to modify database structures without affecting their business information models (Castro et al., 2020).
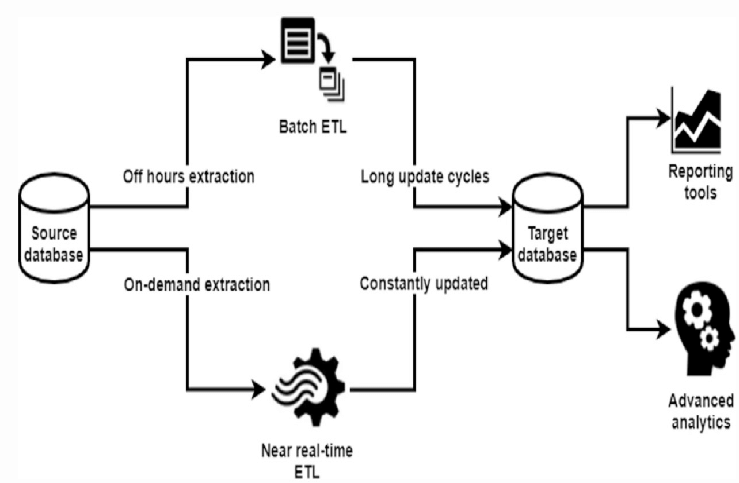
Image Credit: Researchgate.com
Converging batch and stream sources towards near-real-time data architecture
The frequency of updating data warehouse tables is growing as the demand for real-time analytic findings on data warehouses grows, and the time window for completing an ETL (Extract-Transform-Load) task is diminishing (to minutes or seconds). The architecture of data warehouses and ETL maintenance processes is influenced by factors such as data freshness as well as efficiency. In near real-time ETL processes, incremental ETL approaches have been frequently utilized to transmit deltas (insertions/deletions/updates) from source tables to destination warehouse tables rather than recomputing from start. One difference between incremental ETL and materialized view maintenance is that view maintenance jobs are bracketed into internal transactions to make materialized views transactionally consistent with base tables, whereas ETL flows are typically executed by external tools without full transaction support (Qu & Deßloch, 2017). Figure 4, depicts a logical model of an incremental ETL pipeline which may be used to convert daily batch processing to near-real-time ingestion.
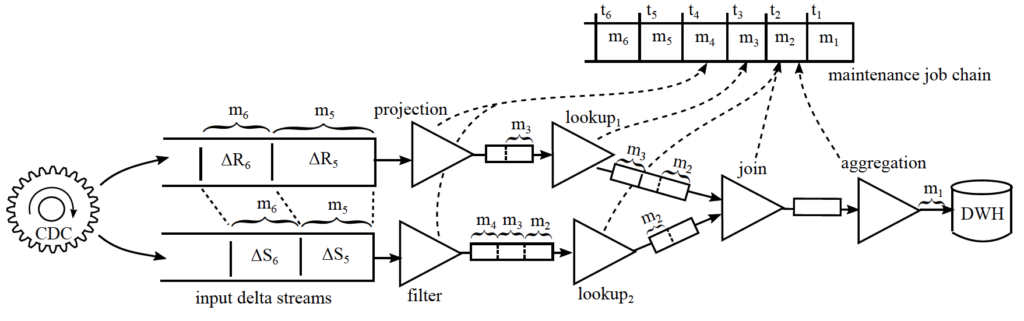
Image Credit: Gesellschaft für Informatik
Streaming analytics platforms, such as Lambda and Kafka are built upon tiered frameworks, hence offering scalability on large amounts of continuous data streams in near-real time. Streams like this emerge organically on social media platforms like Twitter and Facebook (Falk et al., 2017). However, with the ever-increasing utilization of microservice architecture in various industries, several events have valuable information related to customer relation management. When processing large volumes of semi-structured data, there is often a time lag between the point at which data is gathered (producer) and its availability in reports and dashboards (consumer). Often, the delay is caused by the requirement to confirm or at the very least identify granular data. However, in other circumstances, being able to respond quickly to fresh data is more crucial than being 100 percent confident of the data’s veracity (Srinivasan & Ratan, 2018). The reference Lambda architecture on AWS presented in figure 5 leverages several AWS building blocks to integrate batch and stream data ingestion towards a near-real-time data architecture. This architecture leads to a vendor lock-in which might limit the organization towards the adoption of best-of-breed technologies as discussed by Castro et al. (2020).
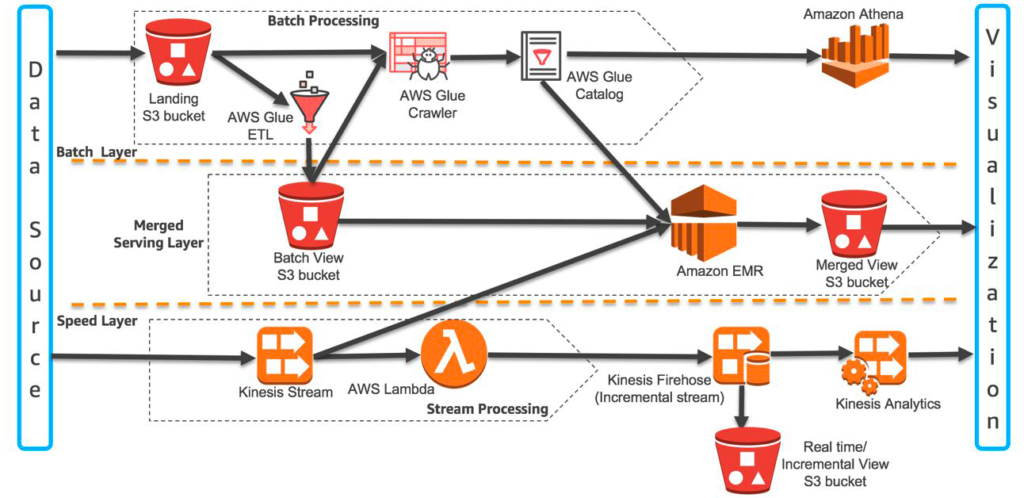
Image Credit: AWS
Falk et al. (2017) addressed the need for real-time prediction decisions required when dealing with large sized or continuous messages, by moving ETL to the messaging layer (Kafka), allowing multiple speed layers such as Spark to perform pure computational tasks. Kafka allows engineers to use query the messaging and format it according to the requirements of the consumer. This functionality makes Kafka an ideal streaming platform by offloading bandwidth and computation on both sides (ETL and consumer).
Key attributes towards achieving near-real-time data architecture
Gorhe (2020), identify 4 key attributes to achieve near-real-time data architecture, specifically:
- Low latency – Latency is defined as the time lag between when a transaction is executed in the transactional source system and when it is loaded into the data warehouse system. A near-real time system should have extremely minimal latency, preferably in minutes, and give the most up-to-date data for business analysis.
- High availability – Typical near real time source systems, such as streaming datasets, are time sensitive, which implies that the data created by them is only accessible for a short length of time. To eliminate inconsistencies, the data warehouse infrastructure should be able to deal with such sources while also making the most use of data distribution and replication mechanisms.
- Minimum disruptions – It is critical for near-real time systems to place as little strain on source systems as possible throughout the extraction process and to use efficient data loading procedures to prevent affecting data warehouse customers’ quality of service.
- High scalability – Scalability in data warehouse settings refers to a system’s capacity to react to a rapid rise or drop in source data volume without affecting overall environment performance. Because the bulk of its sources may create variable data volumes, near-real time systems must be extremely scalable.
Existing tools to transform the data architecture
Distributed applications may also benefit from a multi-cloud environment. Organizations leveraging edge providers can offload certain microservices from the multi-cloud architecture to the Edge to improve performance. Several edge providers such as Microsoft Azure IoT Edge, Amazon Greengrass and IBM Edge Application manager, utilize a containerized approach for IoT. The study performed by Liu (et al., 2021) measured the performance of a microservice model using a vertical plant wall with various sensors connected to Azure Edge cloud. The microservices running in the edge container engine met the <200ms latency. This study demonstrates that splitting applications into small microservices allows relocation of such containers to various locations and platforms (cloud or edge), for increased elasticity and responsiveness.
| Steps | Tools |
|---|---|
| Introduce a DWaaS | Snowflake / Amazon Redshift / Microsoft Azure SQL Data Warehouse |
| Introduce a distributed event streaming platform | Apache Kafka / Google Pub Sub / Azure Event Hubs / Amazon SQS |
| Introduce a data flow platform | Apache NiFi / Talend Data Integration / Azure Data Factory / AWS Glue |
Conclusion
Organization seeking to leverage cloud agnosticism may eliminate vendor-specific tools and utilize containerization to automate and replicate infrastructure. Transforming the data architecture is an elaborate process which requires technical and business expertise. Additionally, such a technological overhaul requires an extensive refactoring of the existing data model to leverage the new near-real-time data points. Hence it comes as no surprise that such a transformation requires several months to adopt. Albeit the extensive effort to transform data architecture, the premise of improving customer loyalty should justify such an undertaking.
References
Azad, M. (2021). 10 pain points in building data warehouse for large banks. Linkedin.com. Retrieved November 21, 2021, from https://www.linkedin.com/pulse/10-pain-points-building-data-warehouse-large-banks-mohammad-azad/
Castro, A., Machado, J., Roggendorf, M. & Soller, H. (2020, June). How to build a data architecture to drive innovation – today and tomorrow. McKinsey Technology. Retrieved November 21, 2021, from https://www.mckinsey.com/~/media/McKinsey/Business%20Functions/McKinsey%20Digital/Our%20Insights/How%20to%20build%20a%20data%20architecture%20to%20drive%20innovation%20today%20and%20tomorrow/How-to-build-a-data-architecture-to-drive-innovation.pdf
Cui, S., & Ding, N. (2018). Construction of a bank customer data warehouse and an application of data mining. Proceedings of the 2018 10th International Conference on Machine Learning and Computing. https://doi.org/10.1145/3195106.3195178
Dageville, B., Cruanes, T., Zukowski, M., Antonov, V., Avanes, A., Bock, J., Claybaugh, J., Engovatov, D., Hentschel, M., Huang, J., Lee, A. W., Motivala, A., Munir, A. Q., Pelley, S., Povinec, P., Rahn, G., Triantafyllis, S., & Unterbrunner, P. (2016). The Snowflake elastic data warehouse. Proceedings of the 2016 International Conference on Management of Data. https://doi.org/10.1145/2882903.2903741
Dessalk, Y. D., Nikolov, N., Matskin, M., Soylu, A., & Roman, D. (2020). Scalable execution of big data workflows using software containers. Proceedings of the 12th International Conference on Management of Digital EcoSystems. https://doi.org/10.1145/3415958.3433082
Falk, E., Gurbani, V. K., & State, R. (2017). Query-able Kafka: An agile data analytics pipeline for mobile wireless networks. Proceedings of the VLDB Endowment, 10(12), 1646–1657. https://doi.org/10.14778/3137765.3137771
Gorhe, S. (2020). ETL in Near-Real Time Environment: Challenges and Opportunities. ResearchGate.com. Retrieved November 21, 2021, from https://www.researchgate.net/profile/Swapnil-Gorhe/publication/340938742_ETL_in_Near-real-time_Environment_A_Review_of_Challenges_and_Possible_Solutions/links/5fbe17d892851c933f5812cd/ETL-in-Near-real-time-Environment-A-Review-of-Challenges-and-Possible-Solutions.pdf
Inmon, W. H. (2011). Building the data warehouse. Wiley.
Kimball, R. (2008). The data warehouse lifecycle toolkit. Wiley.
Korotich, B. (2021, September 27). Data Warehouse Implementation: 10 Tips to implement DWH for a Bank. DICEUS. Retrieved November 21, 2021, from https://diceus.com/implement-data-warehouse-bank-9-months/
Kraetz, D., & Morawski, M. (2021). Architecture patterns – Batch and real-time capabilities. The Digital Journey of Banking and Insurance, 3, 89–104. https://doi.org/10.1007/978-3-030-78821-6_6
Liu, Z., Wu, H., Bai, T., Wang, Y., & Xu, C. (2020). Towards elastic data warehousing by decoupling data management and computation. Proceedings of the 2020 4th International Conference on Cloud and Big Data Computing. https://doi.org/10.1145/3416921.3416935
Mehmood, E., & Anees, T. (2020). Challenges and solutions for processing real-time Big Data Stream: A systematic literature review. IEEE Access, 8, 119123–119143. https://doi.org/10.1109/access.2020.3005268
Mene, R., Westenberger, H., & Husic, H. (2018). Reference models for the standardization and automation of data warehouse architecture including SAP solutions. Retrieved November 21, 2021, from https://cos.bibl.th-koeln.de/frontdoor/deliver/index/docId/725/file/Mene18acos.pdf
Qu, W. & Deßloch, S., (2017). Incremental ETL pipeline scheduling for near real-time data warehouses. In: Mitschang, B., Nicklas, D., Leymann, F., Schöning, H., Herschel, M., Teubner, J., Härder, T., Kopp, O. & Wieland, M. (Hrsg.), Datenbanksysteme für Business, Technologie und Web (BTW 2017). Gesellschaft für Informatik, Bonn. (S. 299-308). Retrieved November 21, 2021, from https://dl.gi.de/bitstream/handle/20.500.12116/636/paper20.pdf?sequence=1&isAllowed=y
Sharma, S., Goyal, S. K., & Kumar, K. (2020). An approach for implementation of cost-effective automated data warehouse system. International Journal of Computer Information Systems and Industrial Management Applications, 12, 033-045. http://www.mirlabs.org/ijcisim/regular_papers_2020/IJCISIM_4.pdf
Srinivasan, R. & Ratan, U. (2018). Lambda architecture for batch and stream processing. AWS. Retrieved November 21, 2021, from https://d0.awsstatic.com/whitepapers/lambda-architecure-on-for-batch-aws.pdf
Yan, J., Jin, Q., Jain, S., Viglas, S. D., & Lee, A. (2018). Snowtrail: Testing with production queries on a cloud database. Proceedings of the Workshop on Testing Database Systems. https://doi.org/10.1145/3209950.3209958
Zdravevski, E., Apanowicz, C., Stencel, K., Slezak, D., & Perner, P. (2019). Scalable cloud-based ETL for self-serving analytics. ResearchGate. Retrieved November 21, 2021, from https://www.researchgate.net/profile/Eftim-Zdravevski/publication/355163966_Scalable_Cloud-based_ETL_for_Self-serving_Analytics/links/61619f8dae47db4e57b388ff/Scalable-Cloud-based-ETL-for-Self-serving-Analytics.pdf